2026 大模型 API 选型指南:Claude / GPT / Gemini / DeepSeek 怎么选
2026 年可用的大模型比以往任何时候都多。Claude 4 系列、GPT-5 系列、Gemini 2.5、DeepSeek V3——每家都在刷榜,每家都说自己最强。
对开发者来说,真正的问题不是「哪个模型最强」,而是**「我的场景该用哪个」**。
本文基于实际开发中的测试和使用经验,从性能、成本、适用场景三个维度做一次系统对比。
主流模型一览
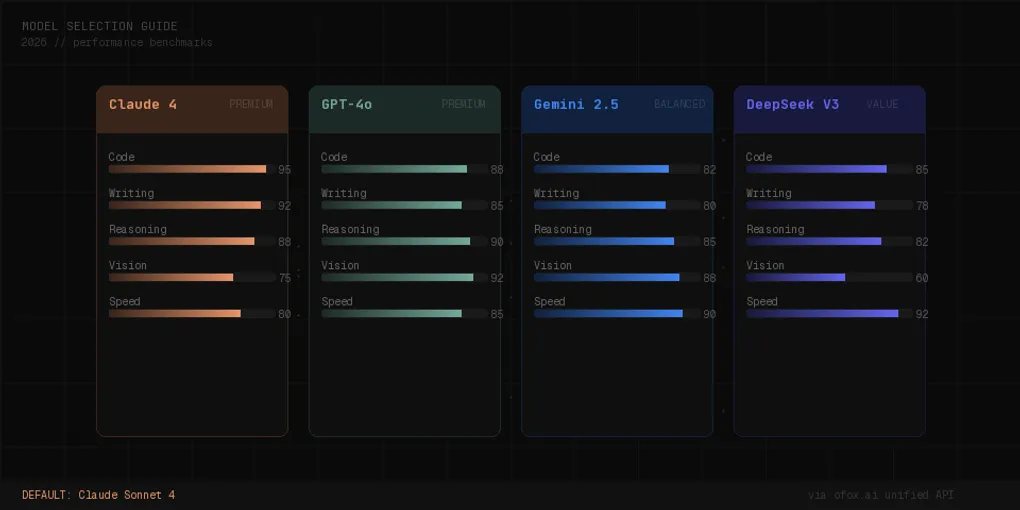
先看看 2026 年各家的当前主力模型:
| 厂商 | 旗舰模型 | 高性价比模型 | 轻量模型 |
|---|---|---|---|
| Anthropic | Claude Opus 4.6 | Claude Sonnet 4.5 | Claude Haiku 4.5 |
| OpenAI | GPT-5 | GPT-4o | GPT-5-mini |
| Gemini 2.5 Pro | Gemini 2.5 Flash | Gemini 2.5 Flash Lite | |
| DeepSeek | DeepSeek V3 | — | — |
每个系列都有「旗舰 → 均衡 → 轻量」的产品分层,选对层级比选对厂商更重要。
按任务类型选模型
代码生成与重构
代码任务对模型的逻辑推理和代码理解能力要求最高。
推荐:Claude Sonnet 4.5 / Claude Opus 4.6
Claude 在代码质量、架构理解和长文件重构方面表现领先。Sonnet 4.5 的性价比尤其突出——性能接近 Opus,成本低很多。
GPT-4o 在代码生成上也很扎实,特别是生成带注释的规范代码。DeepSeek V3 在开源模型中表现出色,适合预算有限的场景。
实用搭配:日常编码用 Claude Sonnet 4.5,复杂架构设计用 Claude Opus 4.6,简单补全用 DeepSeek V3。
文本写作与翻译
写营销文案、技术文档、做翻译或内容改写。
推荐:Claude Sonnet 4.5 / GPT-4o
Claude 的中文写作质量高,语言地道自然。GPT-4o 在英文内容和格式化输出上更稳定。如果做中英互译,Claude 和 GPT-4o 都是不错的选择。
数据分析与推理
处理结构化数据、做数学推理、逻辑判断。
推荐:GPT-5 / Claude Opus 4.6
GPT-5 系列的思维链推理能力突出,适合复杂的多步骤数学和逻辑问题。Claude Opus 4.6 在需要理解大量上下文的分析任务中占优。
多模态(图像理解)
需要模型理解图片内容,做 OCR、图表分析、UI 截图理解等。
推荐:GPT-4o / Gemini 2.5 Pro
GPT-4o 的视觉理解能力成熟稳定,API 调用简单。Gemini 2.5 Pro 支持超长上下文+视觉输入的组合,适合同时处理大量图文混合内容。
超长文档处理
需要处理几万甚至几十万 token 的长文档。
推荐:Gemini 2.5 Pro
Gemini 2.5 Pro 支持百万级 token 上下文窗口,在长文档摘要、跨文档检索方面有明显优势。Claude 的上下文窗口也在扩大,但目前 Gemini 仍然领先。
高吞吐/低延迟场景
在线聊天机器人、实时翻译等对响应速度要求高的场景。
推荐:Claude Haiku 4.5 / GPT-5-mini / Gemini 2.5 Flash Lite
这三个轻量模型的响应速度都在百毫秒级别,成本是旗舰模型的十分之一甚至更低。对于不需要复杂推理的任务,轻量模型完全够用。
成本对比
API 调用成本是选型的重要考量。以下是主流模型的大致价格区间(每百万 token):
| 模型 | 输入价格 | 输出价格 | 定位 |
|---|---|---|---|
| Claude Opus 4.6 | $15 | $75 | 旗舰,复杂任务 |
| Claude Sonnet 4.5 | $3 | $15 | 均衡,主力选择 |
| Claude Haiku 4.5 | $0.25 | $1.25 | 轻量,高吞吐 |
| GPT-4o | $2.5 | $10 | 均衡,多模态 |
| GPT-4o-mini | $0.15 | $0.6 | 轻量,高性价比 |
| Gemini 2.5 Pro | $1.25-2.5 | $5-10 | 长上下文 |
| DeepSeek V3 | $0.27 | $1.10 | 开源旗舰 |
注:价格可能随厂商调整而变化,以各平台实际定价为准。通过 ofox.ai 接入可享受旗舰模型 8 折、开源模型低至 3 折的优惠。
成本优化策略
-
分级调用:简单任务用轻量模型,复杂任务才上旗舰模型。一个项目里同时用 2-3 个不同级别的模型很正常。
-
缓存重复请求:相同的 prompt 不需要重复调用。在应用层做语义缓存可以显著降低成本。
-
控制输出长度:设置合理的
max_tokens,避免模型生成不必要的冗长回复。 -
选对模型尺寸:GPT-5-mini 能做的事不要用 GPT-5。在不影响效果的前提下尽量用轻量模型。
选型决策树
不确定该用哪个模型?按这个流程走:
你的任务需要复杂推理吗?
├── 是 → 是代码/架构相关?
│ ├── 是 → Claude Opus 4.6 / Claude Sonnet 4.5
│ └── 否 → 是数学/逻辑推理?
│ ├── 是 → GPT-5
│ └── 否 → Claude Sonnet 4.5 / GPT-4o
└── 否 → 需要处理超长文档?
├── 是 → Gemini 2.5 Pro
└── 否 → 需要图像理解?
├── 是 → GPT-4o
└── 否 → 对延迟敏感?
├── 是 → Claude Haiku 4.5 / GPT-5-mini
└── 否 → Claude Sonnet 4.5(万能选择)如果还是不确定:从 Claude Sonnet 4.5 开始。它在大多数任务上都能给出不错的结果,性价比高,可以作为默认选择。等发现具体瓶颈后再针对性切换。
用 ofox.ai 灵活切换
选型不是一次性决策。实际项目中经常需要根据任务动态选择模型,或者在新模型发布时快速测试对比。
通过 ofox.ai,你只需要一个 API Key 就能调用上面提到的所有模型。切换模型只需要改 model 参数,不需要改 SDK、改 key、改请求格式。
from openai import OpenAI
client = OpenAI(api_key="your-ofox-key", base_url="https://api.ofox.ai/v1")
# 同一段测试 prompt,跑不同模型对比效果
test_prompt = "分析这段代码的时间复杂度..."
for model in ["anthropic/claude-sonnet-4.5", "openai/gpt-4o", "deepseek/deepseek-v3.2"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": test_prompt}]
)
print(f"=== {model} ===")
print(resp.choices[0].message.content)这种「一套代码跑多模型」的方式,让选型从纸面分析变成实际测试,更快得出结论。
模型能力和价格变化很快,本文基于 2026 年 2 月的信息。建议在实际选型时以各厂商和 ofox.ai 平台的最新数据为准。