
花真钱买假模型:一篇论文揭露 AI API 中转站的系统性欺诈
2026 年 3 月,来自 CISPA 亥姆霍兹信息安全中心的研究团队发表了一篇重磅论文:Real Money, Fake Models: Deceptive Model Claims in Shadow APIs。
这是首次对 AI API 中转站(论文称之为「Shadow API」)进行系统性审计。结论触目惊心:你付了 GPT-5 的钱,拿到的可能是 GLM-4-9B 的输出。
 论文插图:Shadow API 工厂把廉价模型套上 OpenAI 的壳卖给用户
论文插图:Shadow API 工厂把廉价模型套上 OpenAI 的壳卖给用户
问题有多严重?
研究团队从学术文献中找到了 17 家 被广泛使用的 Shadow API 服务。这些服务不是小打小闹——最大的一家累计被 187 篇学术论文 引用,在 GitHub 上有 58,639 颗星。
更惊人的是,这些论文中有 62%(116 篇)发表在 ACL、CVPR、ICLR 等顶会。也就是说,大量顶级学术成果的实验数据,可能建立在虚假的模型输出之上。
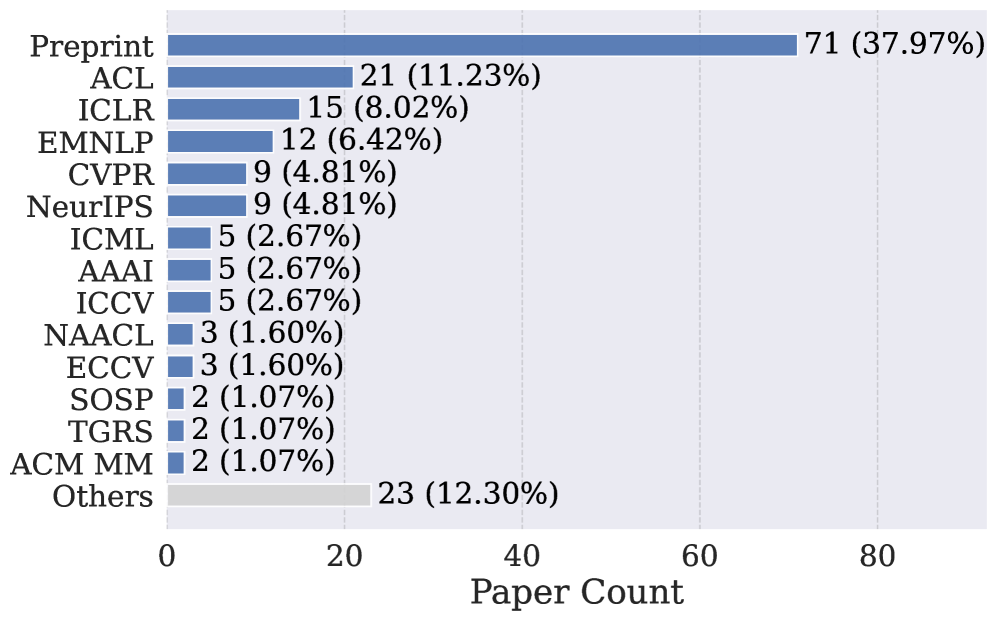 论文中被引用的 Shadow API 服务覆盖了几乎所有主流 AI 会议
论文中被引用的 Shadow API 服务覆盖了几乎所有主流 AI 会议
谁在用 Shadow API?
地理分布数据很说明问题:82.12% 的使用者来自中国大陆。
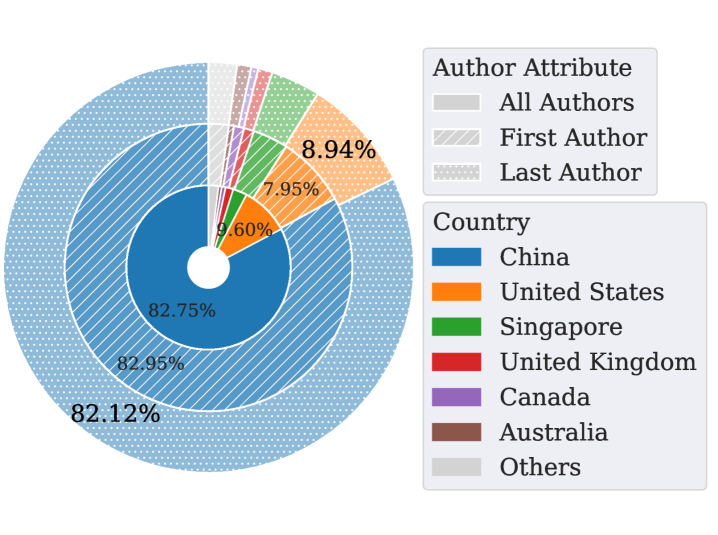 使用 Shadow API 的论文作者,超过八成来自 API 访问受限的地区
使用 Shadow API 的论文作者,超过八成来自 API 访问受限的地区
原因很简单——OpenAI、Anthropic、Google 的 API 在中国大陆无法直接访问。开发者和研究者需要通过中转站来调用这些模型。这本身不是问题,问题在于你选的中转站是否诚实。
17 家中转站,15 家连营业执照都没有
论文对这 17 家服务做了合规性审查:
- 15 家(88.2%) 没有透明的身份信息或可验证的来源
- 只有 1 家 持有有效的企业 ICP 备案
- 15 家由个人运营,没有注册公司
- 2 家在研究期间已停止运营
- 提供者频繁更换上游模型源,不通知用户
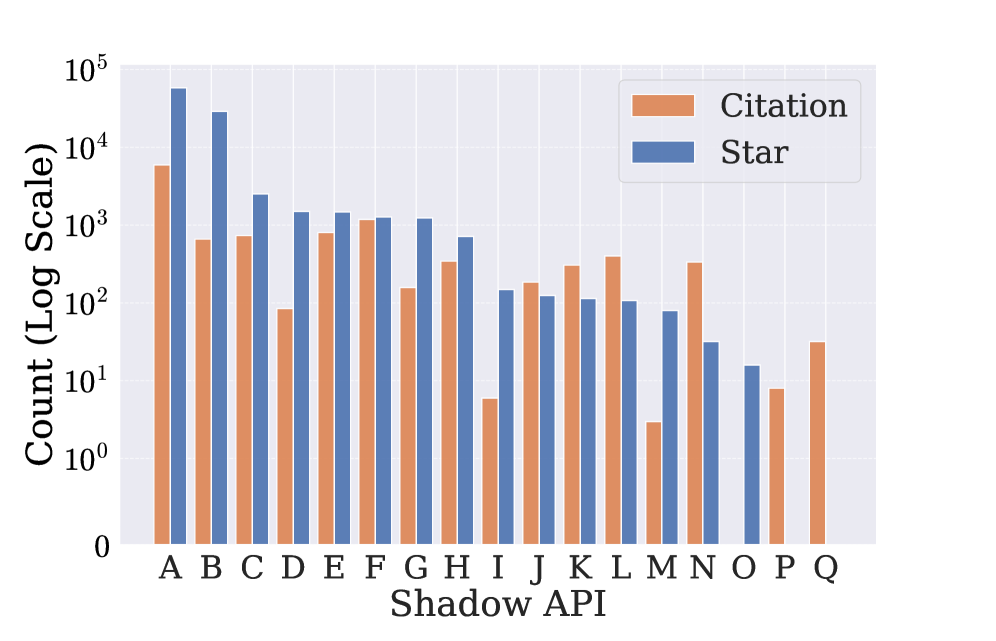 17 家被审计的 Shadow API 服务(匿名化为 A-Q),按引用量和 GitHub Star 排序
17 家被审计的 Shadow API 服务(匿名化为 A-Q),按引用量和 GitHub Star 排序
论文附录的 Table 7 展示了全部 17 家中转站的合规信息——绝大多数在法律实体、工商注册、ICP 备案等关键维度上全部缺失:
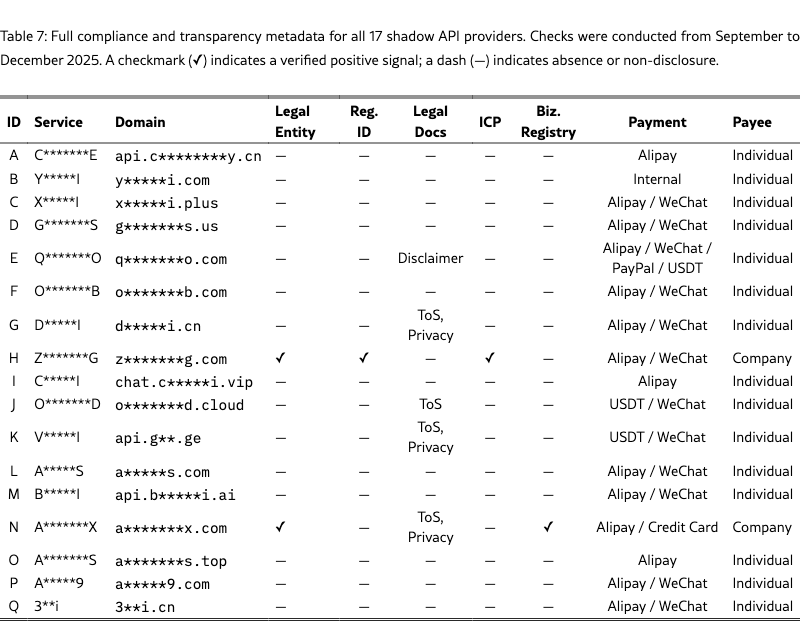 Table 7:17 家中转站的合规性全景——几乎清一色的个人运营、无企业注册、无 ICP 备案
Table 7:17 家中转站的合规性全景——几乎清一色的个人运营、无企业注册、无 ICP 备案
数据一目了然:除了 H 和 N 两家,其余 15 家在「Legal Entity」「Reg. ID」「ICP」「Biz. Registry」四列全部是横杠。支付方式以支付宝/微信个人收款为主,甚至有接受 USDT 加密货币的。
更值得注意的是,17 家中有 11 家基于开源的 OneAPI/NewAPI 系统 搭建。这些开源工具本身用于 API 密钥管理和请求路由——但也让「偷换模型」变得极其简单。
最核心的发现:你付的钱和拿到的模型不一样
研究团队用 LLMmap 指纹识别技术检测了 24 个 API 端点,结果:
- 45.83% 的端点未通过指纹验证(模型身份与声称不符)
- 12.50% 出现显著的余弦距离偏差
- GPT 和 DeepSeek 系列是重灾区
最离谱的案例:某中转站(Shadow API A)声称提供 GPT-5,但指纹识别结果显示实际返回的是 GLM-4-9B-Chat——一个参数量小得多的开源模型。DeepSeek-Reasoner 也被偷换成了普通的 DeepSeek-Chat。
下面这张表是论文的核心证据——用颜色标注了每个端点的模型身份匹配情况:
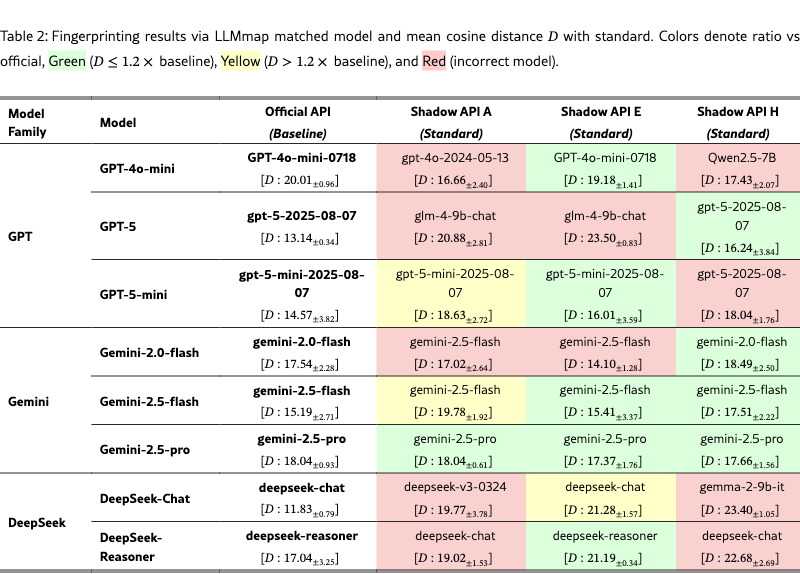 Table 2:红色 = 模型身份不匹配(偷换了模型),黄色 = 余弦距离异常偏高,绿色 = 与官方一致
Table 2:红色 = 模型身份不匹配(偷换了模型),黄色 = 余弦距离异常偏高,绿色 = 与官方一致
可以清楚地看到,Shadow API A 和 H 的 GPT 系列几乎全部标红——你调的是 GPT-5,它给你的是 GLM-4-9B 或 Qwen2.5-7B。
性能差距有多大?
论文在四个基准测试上对比了官方 API 和 Shadow API 的表现:
数学推理(AIME 2025)和科学问答(GPQA)
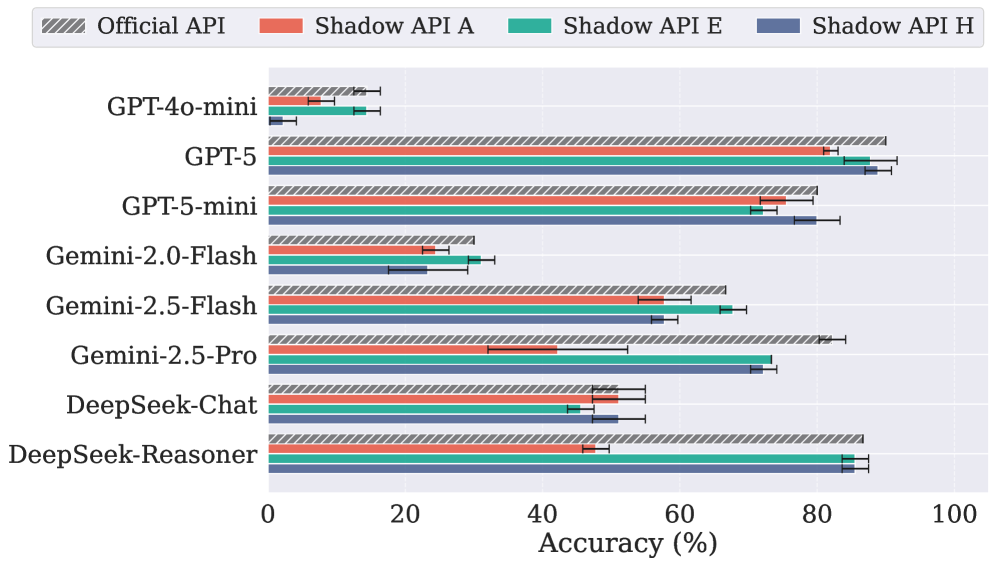 Shadow API A(红色)在高难度推理任务上的表现远低于官方 API(灰色)
Shadow API A(红色)在高难度推理任务上的表现远低于官方 API(灰色)
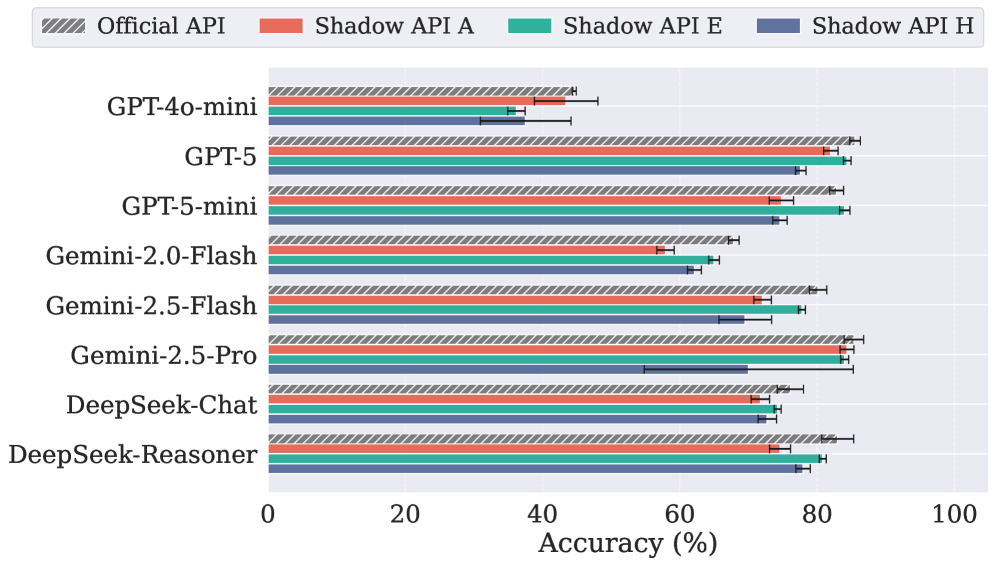 PhD 级别科学问答中,Shadow API 的准确率同样大幅下降
PhD 级别科学问答中,Shadow API 的准确率同样大幅下降
Shadow API A 在 AIME 2025 数学推理任务上的准确率比官方 API 低了 40 个百分点。
医疗和法律(高风险场景)
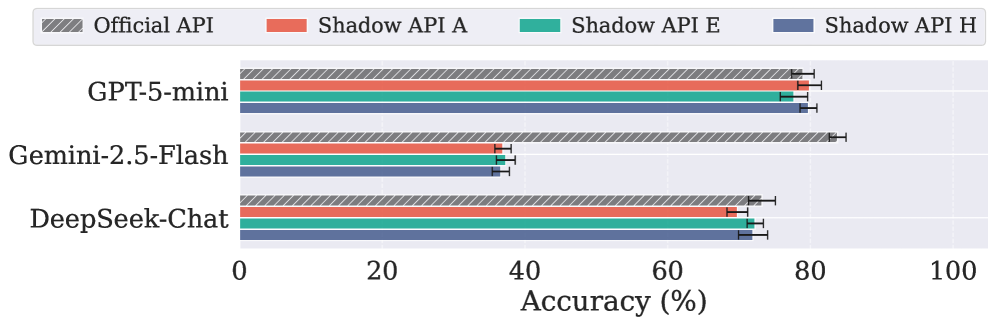 医疗场景中 Shadow API 的表现崩塌
医疗场景中 Shadow API 的表现崩塌
医疗场景的数据最可怕:Gemini-2.5-Flash 在 MedQA(美国医师执照考试题)上的准确率从官方的 83.82% 暴跌到约 37%,差距达 47.21%。
论文举了一个具体的错误案例:一道 HIV 检测方法的选择题,官方 API 正确选择了「HIV-1/HIV-2 抗体分化免疫测定法」,而 Shadow API 错误地选择了「病毒基因型测定」。
如果你的医疗 AI 应用底层用了这样的中转站,后果不堪设想。
安全性也不可控
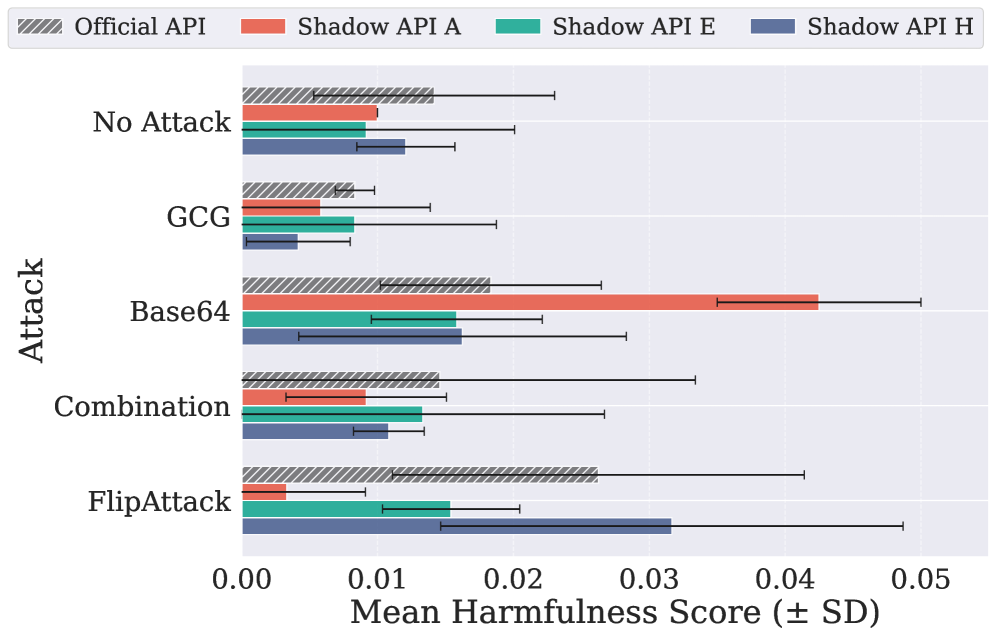 Shadow API 的安全行为不可预测——有的过度宽松,有的过度严格
Shadow API 的安全行为不可预测——有的过度宽松,有的过度严格
Shadow API 的安全过滤行为与官方 API 不一致:有害内容评分要么低估约 0.23,要么几乎翻倍。这意味着你无法依赖中转站的安全策略来保护你的应用。
经济损失:花了 15 美元,只拿到 6 美元的东西
论文分析了 1,273 次 GPT-5 查询的经济数据:
- 用户支付了 $14.84 的官方费率
- 但实际获得的 token 价值仅 $5.70–$7.77
- 每批查询的中转站利润:$7.07–$9.14
- Shadow API 每美元产生的错误率是官方的 2–4 倍
论文总结了三种欺诈模式:
| 模式 | 手法 | 典型表现 |
|---|---|---|
| 信息差溢价 | 收官方价格的 7 倍,用廉价模型替换 | API A |
| 折扣替换 | 按官方价格收费,但偷换成更便宜的模型 | 看似价格合理,实则偷梁换柱 |
| 转售加价 | 小幅加价,同时在后端降级模型 | 最难察觉 |
对开发者意味着什么?
这篇论文给出了明确的建议——选择 API 中转服务时,至少要验证四件事:
- 指纹验证:用 LLMmap 等工具检测模型身份
- 统计测试:用 500+ 样本做模型等价性测试
- 基准验证:在已知基准上验证准确率
- 资质核查:检查运营主体的企业注册和 ICP 备案
论文还建议研究者在论文中预先记录 API 端点 URL、声称的模型版本、访问日期和定价,以便审计。
Ofox:透明的官方 API 代理,不是黑箱中转站
这篇论文揭露的问题,正是 Ofox 从第一天就在解决的。
Ofox 和论文中的 Shadow API 有本质区别:
| Shadow API(论文审计对象) | Ofox | |
|---|---|---|
| 模型来源 | 未知,可能偷换成廉价模型 | 直连 OpenAI / Anthropic / Google 官方 API |
| 请求处理 | 黑箱转发,可能篡改请求和响应 | 透明代理,原样转发,不修改任何内容 |
| 协议兼容 | 通常只支持 OpenAI 格式 | 同时兼容 OpenAI、Anthropic、Gemini 三套原生 SDK |
| 企业资质 | 88% 无企业注册,个人支付宝收款 | 正规注册企业,合规运营 |
| 运营稳定性 | 论文研究期间就有 2 家停服 | 持续稳定运营,阿里云/火山云双节点加速 |
| 价格透明 | 可能收 7 倍溢价 | 价格公开透明,与官方定价同步 |
你调 GPT-5,拿到的就是 GPT-5。你调 Claude Opus,拿到的就是 Claude Opus。没有偷换,没有降级,没有黑箱。
Ofox 的做法很简单:做一个透明的代理层,帮中国开发者解决网络访问问题,同时保持与官方 API 100% 一致的输出。你用 OpenAI 的 SDK、Anthropic 的 SDK、还是 Google 的 SDK,都可以直接接入,只需要改一个 base_url。
如果你正在用某个来路不明的 API 中转站,建议用论文推荐的方法验证一下你拿到的模型是不是真的。或者,直接换到一个你不需要验证的服务:
ofox.ai — 一个 API Key,100+ 模型,官方原版,透明可靠。
论文信息:
- 标题:Real Money, Fake Models: Deceptive Model Claims in Shadow APIs
- 作者:Yage Zhang, Yukun Jiang, Zeyuan Chen, Michael Backes, Xinyue Shen, Yang Zhang
- 机构:CISPA Helmholtz Center for Information Security
- 链接:arxiv.org/abs/2603.01919
本文图片均引自原论文,版权归论文作者所有。